
Note
Go to the end to download the full example code. or to run this example in your browser via Binder
04. Use MPI backend for parallelization#
This example demonstrates how to use the MPI backend for simulating dipoles using HNN-core.
The MPI backend allows running the simulation in parallel across neurons in the network even with a single trial. For this, you will need the MPI related software installed. Note that if you want to simulate in parallel across trials, the Joblib backend allows this without the need to install and configure MPI.
# Authors: Mainak Jas <mjas@mgh.harvard.edu>
# Blake Caldwell <blake_caldwell@brown.edu>
Let us import hnn_core
import os.path as op
import hnn_core
from hnn_core import simulate_dipole, jones_2009_model
Following the alpha example, we add a ~10 Hz “bursty” drive starting at 50 ms and continuing to the end of the simulation. Each burst consists of a pair (2) of spikes, spaced 10 ms apart. The occurrence of each burst is jittered by a random, normally distributed amount (20 ms standard deviation). We repeat the burst train 10 times, each time with unique randomization.
net = jones_2009_model()
weights_ampa = {'L2_pyramidal': 5.4e-5, 'L5_pyramidal': 5.4e-5}
net.add_bursty_drive(
'bursty', tstart=50., burst_rate=10, burst_std=20., numspikes=2,
spike_isi=10, n_drive_cells=10, location='distal',
weights_ampa=weights_ampa, event_seed=278)
Finally, to simulate we use the
MPIBackend class. This will
start the simulation across the number of processors (cores) specified by
n_procs using MPI. The 'mpiexec' launcher is used from
openmpi, which must be installed on the system
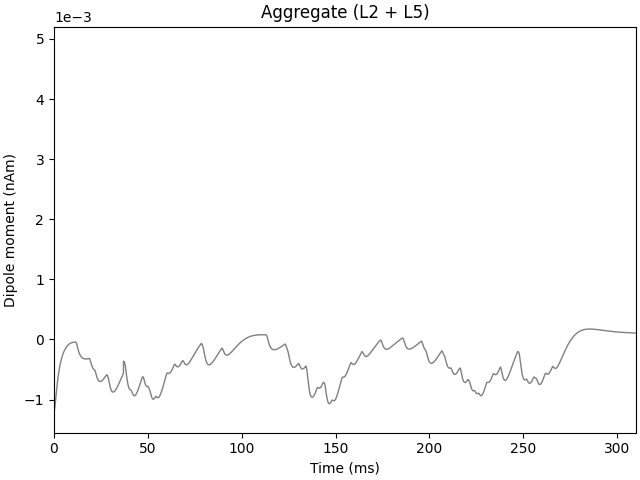
MPI will run 1 trial(s) sequentially by distributing network neurons over 2 processes.
/opt/anaconda3/envs/hc12/bin/nrniv:10: DeprecationWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html
from pkg_resources import working_set
/opt/anaconda3/envs/hc12/bin/nrniv:10: DeprecationWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html
from pkg_resources import working_set
numprocs=2
Loading custom mechanism files from /Users/austinsoplata/rep/brn/hnn-core/hnn_core/mod/arm64/.libs/libnrnmech.so
Building the NEURON model
Loading custom mechanism files from /Users/austinsoplata/rep/brn/hnn-core/hnn_core/mod/arm64/.libs/libnrnmech.so
[Done]
Trial 1: 0.03 ms...
Trial 1: 10.0 ms...
Trial 1: 20.0 ms...
Trial 1: 30.0 ms...
Trial 1: 40.0 ms...
Trial 1: 50.0 ms...
Trial 1: 60.0 ms...
Trial 1: 70.0 ms...
Trial 1: 80.0 ms...
Trial 1: 90.0 ms...
Trial 1: 100.0 ms...
Trial 1: 110.0 ms...
Trial 1: 120.0 ms...
Trial 1: 130.0 ms...
Trial 1: 140.0 ms...
Trial 1: 150.0 ms...
Trial 1: 160.0 ms...
Trial 1: 170.0 ms...
Trial 1: 180.0 ms...
Trial 1: 190.0 ms...
Trial 1: 200.0 ms...
Trial 1: 210.0 ms...
Trial 1: 220.0 ms...
Trial 1: 230.0 ms...
Trial 1: 240.0 ms...
Trial 1: 250.0 ms...
Trial 1: 260.0 ms...
Trial 1: 270.0 ms...
Trial 1: 280.0 ms...
Trial 1: 290.0 ms...
Trial 1: 300.0 ms...
<Figure size 640x480 with 1 Axes>
Total running time of the script: (0 minutes 9.795 seconds)